让建站和SEO变得简单
让不懂建站的用户快速建站,让会建站的提高建站效率!

让不懂建站的用户快速建站,让会建站的提高建站效率!

DeepSeek开源新模子:用视觉样式杀青高下文压缩网上炒股配资。
10月20日,DeepSeek晓示开源最新大模子DeepSeek-OCR。所谓的OCR,据DeepSeek在论文中解释称,是通过光学2D映射压缩长高下文可行性的初步讨论。DeepSeek-OCR由两部分组成:DeepEncoder和看成解码器的DeepSeek3B-MoE-A570M。DeepEncoder看成中枢引擎,设计为在高永诀率输入下保握低激活,同期杀青高压缩比,以确保视觉tokens数目优化且可科罚。
平凡而言,这是一种视觉-文本压缩范式,通过用小数的视觉token来默示原来需要无数文本token的实践,以此缩小大模子的筹办支拨。
据公布的论文名单清晰,该神志由DeepSeek三位讨论员Haoran Wei、Yaofeng Sun、Yukun Li共同完成,但这三位中枢作家王人颇为低调,其中一作作家Haoran Wei曾在阶跃星辰责任过,曾主导成就旨在杀青“第二代 OCR”的GOT-OCR2.0系统。

DeepSeek-OCR的架构分为两部分。一是DeepEncoder,一个专为高压缩、高永诀率文档处理设计的视觉编码器;二是DeepSeek3B-MoE,一个轻量级夹杂内行讲话解码器。这款刚开源不久的新模子,发布后就得到外洋科技媒体闲居吟唱,有网友盛赞:“这是AI的JPEG时候。”
前特斯拉AI总监、OpenAI独创成员安德烈·卡帕西(Andrej Karpathy)在应付媒体高度评价DeepSeek的新模子,他默示,我方绝顶心爱新的DeepSeek-OCR论文,“它是一个很好的OCR模子(可能比dots略略差一丝),是的,数据网罗等等,但非论如何王人不迫切。对我来说更预料的部分(尤其是看成一个以筹办机视觉为中枢,暂时伪装成当然讲话的东说念主)是像素是否比文本更适结合为LLM的输入。看成输入,文本标志是否奢华且恶运。”
把柄他的设计,粗略所有LLM的输入王人只应该是图像。即即是纯文本实践,也应该先渲染成图片再输入给模子,其中根由包括:信息压缩效果更高、像素更通用、因循双向重眼力、可淘汰存在安全隐患的分词器(Tokenizer)。
特斯拉独创东说念主马斯克(Elon Musk)也现身驳斥区,并默示:“从永久来看,AI模子跳跃99%的输入和输出王人将是光子,莫得其他任何东西不错范围化。”
着名科技媒体《麻省理工科技驳斥》解释称,DeepEncoder是所有这个词系统的要道所在。它的设计认识在于,在处理高永诀率输入图像的同期,保握较低的激活内存,并杀青极高的压缩比。为达到这一认识,DeepEncoder交融两种庄重的视觉模子架构:SAM(Segment Anything Model)和 CLIP(Contrastive Language–Image Pre-training)。前者以窗口重眼力机制(window attention)见长,擅所长理局部细节,组成编码器的前半部分;后者则依赖密集的全局重眼力机制(global attention),能够拿获举座常识信息。
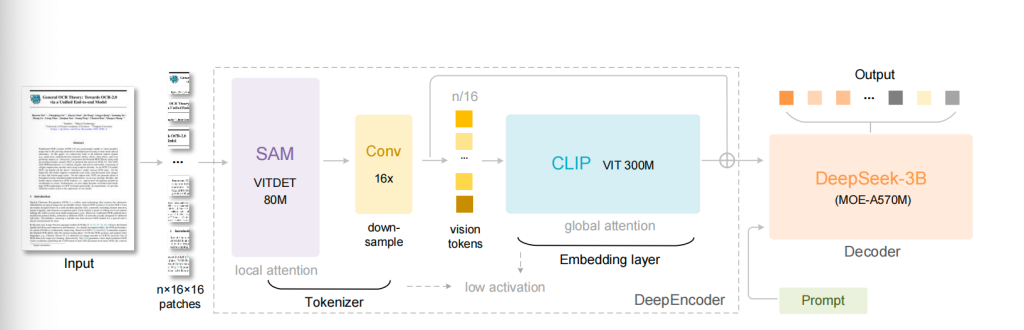
《麻省理工科技驳斥》默示,除了文本识别性能,DeepSeek-OCR还具备较强的“深度解析”才略。这收货于其熟识数据中包含了图表、化学分子式、几何图形等各种化的视觉实践。因此,模子不仅能识别设施文本,还能对文档中镶嵌的复杂元素进行结构化解析。举例,它不错将证实中的图表调度为表格数据,将化学文件中的分子式输出为SMILES才略,或解析几何图形中的线段联系。这种特出传统文本识别的才略,拓展了其在金融、科研、解释等专科鸿沟的讹诈空间。
DeepSeek先容,实验标明,当文本tokens数目在视觉tokens的10倍以内(即压缩比<10×)时,模子可达到97%的OCR精度。即使在20×压缩比下,OCR精度仍保握在约60%。这为历史长高下文压缩和LLM中的追思渐忘机制等讨论鸿沟展示可不雅出路。
DeepSeek-OCR还初步考据高下文光学压缩的可行性,证明模子不错从小数视觉tokens中灵验解码跳跃10倍数目的文本tokens。DeepSeek-OCR亦然一个高度实用的模子,可大范围分娩预熟识数据,“改日,咱们将进行数字-光学文本交错预熟识、大海捞针测试等进一步评估,陆续推进这一有出路的讨论标的。”
据外洋科技媒体分析,讨论团队默示,在基准测试中,DeepSeek-OCR优于多个主流模子,且使用的视觉tokens数目少得多。此外,单张A100-40G GPU每天可生成跳跃20万页的熟识数据,可为大型讲话模子和视觉-讲话模子的成就提供因循。
前网易副总裁、杭州讨论院实践院长汪源发文默示,DeepSeek-OCR模子是一个有益能“读懂”图片里翰墨的AI模子。但利害的所在不是浅易“识字”,是聘请了一种相等新颖的想路:把翰墨当成图片来处理和压缩。
汪源以为,不错把它设想成一个超等高效的“视觉压缩器”,传统的AI模子是径直“读”文本,但 DeepSeek-OCR 是先“看”文本的图像,然后把一页文档的图片信息高度压缩成很少的视觉tokens。DeepSeek-OCR的才略强在能把一篇1000字的著述,压缩成100个视觉tokens。在十倍的压缩下,识别准确率不错达到96.5%。

股票配资交易时间_实盘配资执行规则提示:本文来自互联网,不代表本网站观点。